Streamlining Data Quality: The Role of Automated Ingestion & Data Quality (AIDQ)

Rohini

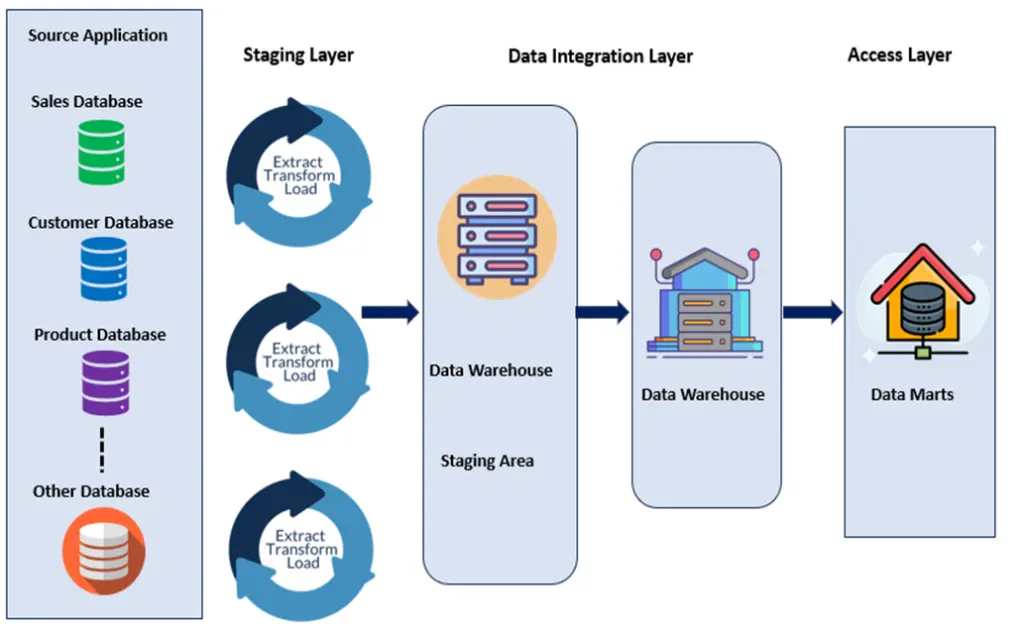
Most of the ETL tool-based data warehouse uses a 3-layer architecture or framework. Some protocols can add up to one more layer based on the requirement. It’s a standard practice to use Raw, Staging, and Curated layers to perform their functions, also called bronze, silver, and gold access layers.
Some of the standard frameworks are DI (Data Ingestion), DQ (Data Quality), DIDQ (Data Ingestion and Data Quality), and Automated Ingestion & Data Quality (AIDQ). All these data operations are performed by the Pipelines in ADF (Azure Data Factory), which are scheduled based on the off time of the business. The representation below shows how the data flow or interaction happens between different layers.
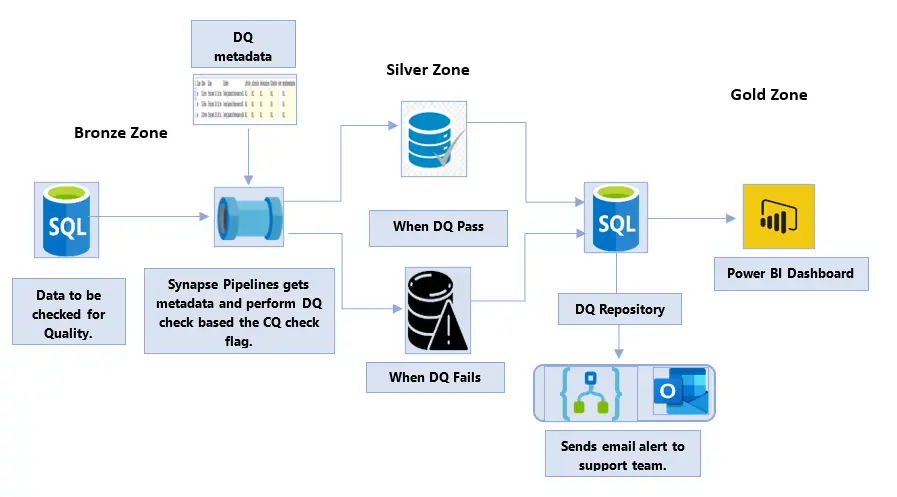
Over the years, the ETL frameworks have evolved to adopt modern and reusable frameworks that define a well-defined process and best practices with utmost TCO (Total Cost of Ownership) and ROI (Return of Investment). WinWire has developed the Automated Ingestion & Data Quality (AIDQ) framework, which fits into the best practices of cost, time, maintenance, process, and ease of use. Below is the high-level architectural representation of the same.
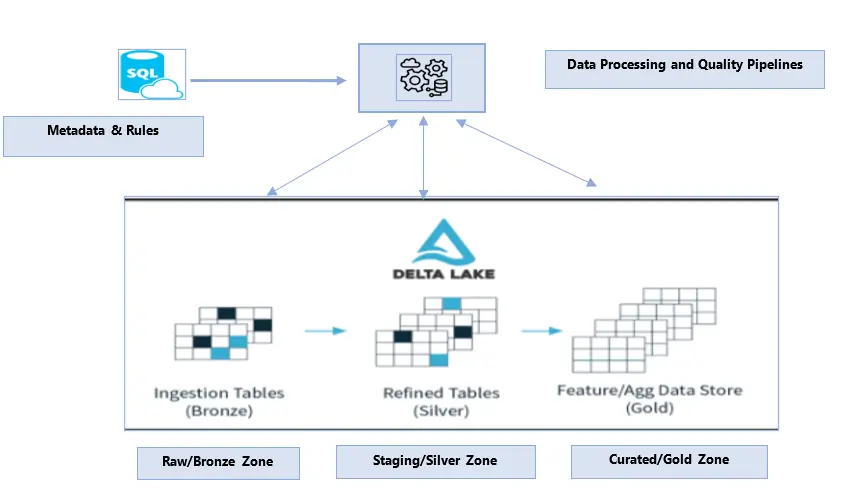
Features – Automated Ingestion & Data Quality (AIDQ)
- Data movement from the source to the data lake and between data zones is driven by metadata.
- Bronze, Silver, and Gold are the primary data zones or layers – where raw data has unfiltered data from multiple sources.
- The bronze layer undergoes the Schema check data validation.
- The silver layer undergoes the DQ-checked data validation.
- The Gold layer undergoes the cleaning and the data load process, where the data is ready for the consumption layer.
- The consumption layer can be anything from the report’s formats like Power BI or Tableau reports, a web application, or an API Endpoint based on the end user’s requirement.
- Rules are defined on column-data type, making it independent of schema structure.
- Each data file generated for an entity has the entity’s schema file. One, share needs a schema file and a data file from the file share to process data.
- Rules are implemented as Python functions. New functions can be created as new rules are added to the system.
- Rules are primarily for data validation and quality, which applies to data in the raw zone. Data that passes these validation and quality rules is moved to the Staging zone.
Automated Ingestion & Data Quality Framework Benefits Over Other Frameworks
- Overall time consumption is reduced by 50% of the actual time taken.
- Reusable data platform assets
- Metadata-Driven Ingestion using Control & Configuration Tables
- Rule-based Data Quality validation.
- Standardized deployable artifacts and minimal maintenance.
Common concerns/Challenges mentioned below can be resolved using Automated Ingestion & Data Quality validation techniques.
- Datatype mismatch
- Data truncation issue
- Calculation or Rule related bugs
- Non-standard formats of heterogeneous data.
- Data Loss due to massive data
- Unstable testing environment
- Duplicate data issues
- Incorrect/Incomplete data
- Huge volume of data
- Difficulty in building the exact and practical test data.
Conclusion
Data is the pillar of any organization, and ETL testing supervises the ETL process to maintain the meaningfulness of the data. A proper framework is required to help validate the core issues, reducing errors with lower maintenance costs and defining the rules.
A rigid and robust framework in place can help in data ingestion, validate the business rules and needs, and provide extensive support for multiple data sources. The Framework is designed to be highly configurable and sustainable, where support is flexible enough for users’ ease of use and helps in notifying and diversifying.




